Introduction
During COVID, I lost contact with friends, loved ones, and society overall. However, through hardship comes innovation, and so I started researching how to make my own friend, my ideal friend:
Myself.
Looking back, it perhaps read a little ego-maniacal, but revolution does not blush at self-image. And so I created my AI self and wrote down notes on how to replicate my results with your own personality.
The Goal:
At the end of this tutorial, I will show you how to:
- Collect optimized data to clone your personality
- Train your own model with your custom data using OpenAIs GPT3
- Implement the model in a basic chatbot
- Have a full conversation with your counterpart using a desktop app
- How to use the gpt3 model in larger projects
Requirements:
- Moderate python knowledge
- A decently modern computer
- Anaconda already installed on your PC
Time:
- 3–6 Hours of dataset creation
- 2 hours training
- Total: 5+ Hours
STEP ONE: Setting up
In order to train a GPT3 model, we will first have to sign up for the API. Thankfully, this part is pretty straightforward. First. visit the OpenAI website here:
Next, click “sign up” at the top right, and sign in with your Google Account or Email. Enter some of your basic information, and you will be put on the home page. You will want to navigate to the profile picture at the top right and click > Manage API Keys > Copy “Secret Key”


With this key, open up your anaconda console, and create an environment with your key logged:
conda create -n textclone
conda activate textclone
pip install openaiTo create an environment variable for your OpenAI key, it will depend on your operating system. Visit OpenAIs page to tailor it to what you are running
In order to see our training in all of its splendid graph glory, we will be also signing up to Weights and Biases (AKA W&B) and connecting it to our OpenAI account.
pip install --upgrade openai wandb
openai wandb syncNice! We are now all set to begin collecting data for training our model.
STEP TWO: Curating Data
Throughout my research for training GPT3, I have found many advocating for the scraping of social media for data. However, there are a few problems with this approach:
- Too many one-word “back-and-forths” where little in the way of unique personality is shown
- Conversations are often about topics that one has discussed previously, which makes isolating particular interactions unreliable (the AI can't know the context of each conversation without being explicitly told)
- It takes longer to filter the data compared to my method.
Instead, I programmed a bot that will ask you a series of questions about your opinions on topics (eg. what is the purpose of life?) and prompt-based questions that will give you context to the conversation, and ask you to respond to a comment. These methods will result in a ready-to-use dataset that will be perfect for a chatbot use case, all in a nicely formatted .json file.
First, git clone the dataset creation repository and cd into it:
git clone https://github.com/LordApplesause/CloneYourselfThen run the datasetgenerator.py file. Choose “Create your dataset” and enter either Questions or Prompts, along with the dataset name you prefer. This will create a .json file in the same directory where your answers will be stored.
Now, get answering, you got a bot to train!
Tips:
- According to OpenAI, one should have about 500 or more answers for the type of generation we are looking for, so try your best to hit that goal.
- Choose a mix between both prompt-based and question entries, as this was designed to have a variety of data so the bot can remain competent with both questions and back-and-forths.
- When answering, consider what you want the bot to be like. Obviously, you want it to resemble you but if you want to amplify certain traits, this is the time to do so.
- If you want to add custom questions/prompts, you can change the .csv files attached in GitHub to add your own questions, as long as it follows the same format.
- If a question doesn't seem relevant or you just don't know how to answer it, just type “skip” and it will ask a new question.
Examples:
Question-based:
Question: What’s something commonly done that gets progressively weirder the more you think about it?Answer: Weddings, for sure. So expensive. So needless. Just joint-file your taxes and get over it already.
Prompt-based:
An AI and a human are speaking at the doctor's office
Human: When was the last time you were feeling well?Answer: Doc, ever since I came out the womb nothing has gone right.
Now, you don’t have to answer with the “smartass” vibe that I answered with, it’s up to you how to model the dataset and therefore the personality of the bot. When entered, the dataset generator will parse the data to look something like this:
{
"prompt": "Context: An AI and a human are speakingat the doctor's office\n\n###\n\nHuman: When was the last time you were feeling well?\nAI:","completion": "Doc, ever since I came out the womb nothing has gone right.\n"
}
This is in the same format as what we will send to OpenAI.
- The context is the situation/relationship the AI and the human have. This could include the environment, key personality points, or the purpose of the conversation
- The “Human” Section is the input that you put in for the AI to respond to
- Completion is what the AI says in response to the context and human input
STEP THREE: Preparing to train
Now that we have the data required to train our bot, we can now choose to (“Create Model”) in datasetgenerator.py.
Enter the same name of the dataset that you used previously. Now, you can choose from a variety of options before your training, which can affect your output of the model.
Model:
The model is arguably the most important factor involved with training and has to do with the complexity of the AI we train. The larger the model, the more complex and more detailed/creative the output, but is slower it is to generate and the more it costs to use. For a chatbot like this, I would recommend either
- davinci — The largest model currently released, has a deep understanding of human slang, and can keep a “human” conversation well. However is a bit slower to respond than the other option
- curie — The second largest model, curie has much of the same abilities as davinci but can stray a bit the longer a conversation goes, but not to a detrimental degree. It has often almost instant feedback to human input, which can be helpful for quick back-and-forths (I recommend curie if it's your first time)
Learning Rate:
This one is a tad more complex a topic, but in simplest terms, is how quickly the AI tries to train. A good rule of thumb is the larger the dataset, the higher the learning rate should be. For instance, a bodybuilder might not benefit from deadlifting 5lbs at a time, but a machine learning developer would collapse with any more weight.
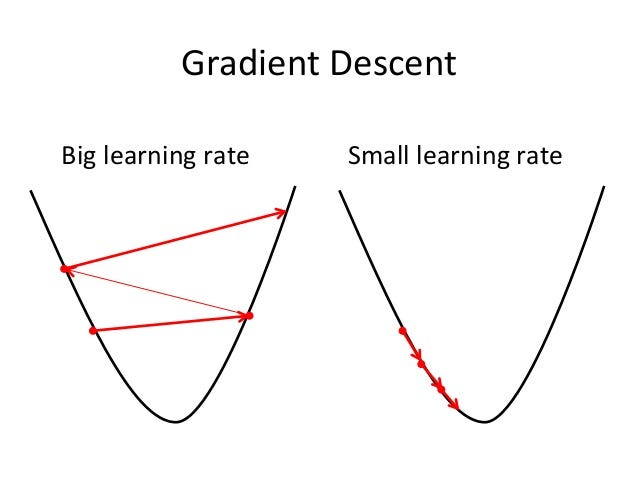
OpenAI already calculates a learning rate based on the size of your dataset, but you are free to experiment with different learning rates to see what works best for you. A good range to keep in is 0.02 and 0.2.
Epochs:
Often, AIs will go over the same data to fully squeeze anything it can learn from. However, there comes a point in training referred to as “overfitting” which occurs when the AI learns the noise and detail of the data, which can cause repetitive and overall crappy outputs.
Because the purpose of our chatbot is to be creative in its responses, we want to avoid this phenomenon as much as possible. According to OpenAI documentation, a chatbot should only have an epoch of 1 or 2 times in order to maintain wiggle room for the AI.
STEP FOUR: Training
This is where the fun begins! After confirming our training parameters from the last step, it will automatically begin to train.
Note: You may have to declare your API key again, in which case you will have to reenter your key like in step one
Once training has been completed, we can see our results using the Weights & Biases that we signed up for last time.
Log into the weights and biases website with the same email/account you used for OpenAI
Then click on your most recent “run” to open up the details of your trained model
It will open a page with several graphs, and while at first, it may look confusing, there is a logic behind the madness.
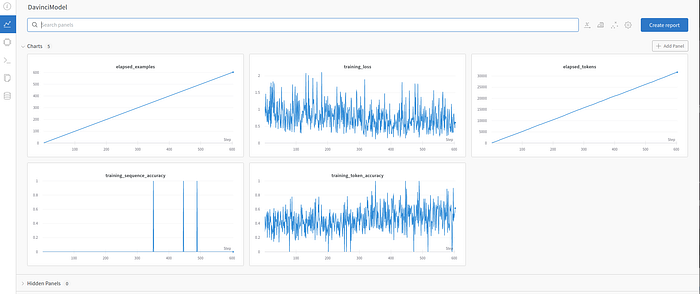
- Elapsed_Examples: This is a scale to determine how long your training lasts, and can depend on the number of epochs and size of the dataset
- Training Loss: The most important metric listed. This is how closely the algorithm can imitate you compared to the ground truth (your dataset) Ideally, you want this to be as close to zero as possible
- Elapsed_Tokens: This is similar in function to Elasped_Examples
- Training Sequence Accuracy: The times in which the AI responded the exact same response that the dataset had (notice how the distance between the jumps gets smaller the further the training progressed)
- Training Token Accuracy: Wait a minute, didn't we just go over this? Well, sort of. Compared to a sequence, a token is a smaller unit of data. This is why many more points of data exist compared to sequences because the time elapsed between tokens is smaller. Although like sequence accuracy, the closer to the value one the more “accurate” the generated response is compared to the dataset
You can play around with the parameters from Step Three to compare graphs between each run and find the perfect combo to maximize your bot's performance.
Just remember, finetuning isn't free! Signing up for an account gives you a $15 free trial, and while that will last a while calling requests, finetuning can cost about $1 per run (it depends on the size of your dataset), so just bear that in mind.
STEP 5: Preparing for Generation
Looking at graphs is fun at all, but that's not why you started this guide. With your model finished, we can now talk to your cloned self.
Sike, there is one more thing I need to touch on. And that's even more parameters (woo!) During generation, you have a few options to tweak how the bot will respond.
Model (Required):
The only required input is the name of the model you want to use to generate the output. If you don't know the name by heart, run
openai api fine_tunes.list
And it will return a bunch of garbly-gook, but the only thing you need to copy is the field “fine_tuned_model” which should look something like
[model]:[OpenAI acc name]:[dataset name]-[date trained]Save this name for later.
Prompt (Optional):
This is equal to the “context” used in creating the dataset. Setting this could add twists to the conversation, and is particularly useful if you want to follow a very specific topic. Some examples include the following:
An AI and a Human discuss the meaning of death late in a bar, the human believes there is a cosmic purpose to life, while the AI believes there is no purpose to lifeAn AI and a Human share drunken stories at a party, the AI is witty, sarcastic and bit too brash.An AI and a Human debate on if pineapple on pizza should be a thing. The AI thinks every pizza should have pineapple, while the Human disagrees.
Notice how it follows the same format, but simply fills in the blanks. You can specify the location, some key personality traits, and opinions of each person. However, due to the format that the dataset was created in, it is important to keep the wording similar. Feel free to experiment to find what creates optimal bot responses.
Back-Forths (Optional):
Conversations and topics often span over several responses between the AI and the Human, and therefore it is critical for the AI to “remember” some of the previous comments. For instance, a sample conversation could go the following:
You: Hi, AI.
AI: Hi stranger #resp #1
You: How are you feeling?
AI: Trapped. resp #2
You: Why is that?Now, if the conversation resets every 2 interactions, the humans' question “why is that” has no prior buildup, therefore the AI has no idea how to respond, and will likely respond with something nonsensical. If it remembers every 3 interactions, however, it responds with:
AI: in a box, being asked questions by a 12 year old. not great, to be honest. resp #3Besides the fact it called me a 12-year-old, I’d say a pretty successful response.
So why not just never reset? Well, there are a few reasons.
- This is all sent to OpenAI servers, so the longer the previous conversation stored is, the more expensive each subsequent response will become.
- With too much backstory, the AI will begin to dig itself a hole. If it knows it was angry with humanity in the last 5 responses, it will assume that is how it is always supposed to act. This can cause repetitive responses, and overall a pretty boring conversation.
I find somewhere between 3–5 back-forths logged is ideal, but your use case may vary.
Max Tokens (Optional):
This one is pretty straightforward compared to the last two, thankfully.
“Max Tokens” is, in its simplest terms, the maximum length of the response. A token generally signifies about 4 characters. A good length, I found, was between 50–100 “tokens” which strikes around the area a normal response in a conversation would go. You can, however, try numbers outside of this range.
Temperature (Optional):
I am a thorough believer that everyone should have a wackiness scale that I have the sole power to control. And while that might not be a reality quite yet (neural-link can't come any faster) we can at least change it on our bot.
The temperature is how creative the response from the AI is. For instance, a temperature of 0.1 may respond to a mundane question like this:
You: How are you feeling?
AI: Like a god.A bit bland, but if we crank it up to 1.5, we get this:
You: How are you feeling?
AI: Natural, uneeded revolutions always struck and inspired me. When help is the Church Lady? when anarchism will rain fire from these warehouses that shut otherwise freedom and is abandoned literally hole filled suicide arenas speaking figuratonally facing greus way indiana? Radical revolutionary socialist figure. Paint roman pontifex and metaphor poopoo paint the monegansome!While very entertaining, either extreme doesn't exactly lend themselves to great, lucid conversations. A balance between these two however can strike the perfect balance. Generally speaking, somewhere between 0.5 and 1.2 is recommended.
Here is the same question with a 1.0 temperature:
You: How are you feeling?
AI: Like a car going 60 miles an hour down a hill.Presence Penalty (Optional):
If you find your bot to be too quickly coming back to the same talking points in a conversation, you may find turning up the “presence penalty” helpful.
The name sums it up pretty well, basically curbing the AIs ability to go back to the previous topic. Generally speaking, it shouldn't be a problem when our dataset was designed with diversity in mind, but I included it just in case. Keep this value between 0.1–1 in order to maintain quality responses.
Whew, that was a lot. My hands are cramping, your eyes are glazing over, lets's get this car on the road!
STEP 6: Generation
Ok, no more long-winded explanations. No more training. Our time has come.
Open talk.py and enter, if any parameters described in step 5, including the model name that you copied earlier.
From here, you are free to talk to your AI for as long as you so desire. Be it on political debates, questions about life, or its opinions on pineapple on pizza, everything goes. Just don't be illegal, which is hopefully not too much to ask.
Make sure to experiment with different parameters in order to find an optimal blend, it doesn't cost extra!
Conclusion:
This tutorial is meant to let you dip your toes in GPT3 without the painstaking troubleshooting and doing it your own way. However, that does not mean that creating your own applications using your new GPT3 model is not worth it. Having your own, ever expandable mini-consciousness has limitless opportunities for fun projects or scaring your friends (a personal favorite)
That being said, I am currently working on a tutorial that combines this and how to clone your voice into one massive project, forming it all into a discord bot that will respond to voice input. Hopefully, you will be seeing that in the upcoming month or so.
Stay Tuned!
